

 Fin dannée, Intel devrait nous gratifier dune nouvelle génération de processeurs, dénommée Cascade Lake, déclinée notamment côté serveur avec ses Xeon (on devrait voir Cooper Lake en 2019 et Ice Lake en 2020, selon les plans actuels). Lors de la conférence Hot Chips, la société a pris un peu de temps pour détailler ce que lon verra avec cette nouvelle architecture.
Fin dannée, Intel devrait nous gratifier dune nouvelle génération de processeurs, dénommée Cascade Lake, déclinée notamment côté serveur avec ses Xeon (on devrait voir Cooper Lake en 2019 et Ice Lake en 2020, selon les plans actuels). Lors de la conférence Hot Chips, la société a pris un peu de temps pour détailler ce que lon verra avec cette nouvelle architecture.Rapidement : des instructions spécifiques à lapprentissage profond (en réutilisant les unités AVX-512) et des protections matérielles contre certaines failles de type Spectre/Meltdown. Pour le reste, Cascade Lake reste très similaire à Skylake : maximum vingt-huit curs, maximum 38,5 Mo de cache de dernier niveau (L3), maximum trois canaux UPI pour la communication avec dautres processeurs sur la même carte mère, maximum quarante-huit canaux PCIe, maximum six canaux de mémoire. Il sagit donc principalement dune amélioration incrémentale sur bon nombre de critères, cest-à-dire que Cascade Lake pourra monter un peu plus haut en fréquence et consommer un peu moins dénergie, par exemple.
Côté sécurité
Ce dernier point est particulièrement important : les protections actuellement mises en place ont un impact mesurable sur la performance, bon nombre dentreprises semblent prêtes à payer le prix fort pour obtenir un processeur protégé contre ces vecteurs dattaque. Alors que, pour les processeurs actuels, les protections ne peuvent être implémentées quau niveau logiciel (du système dexploitation, notamment, avec un coût en performance non négligeable) ou dans le microcode, pour Cascade Lake, Intel prévoit une implémentation aboutie au niveau de la microarchitecture du processeur sans impact sur la performance.
Sur les six types dattaque, trois seront donc traitées directement au niveau matériel : Spectre variant 2, Meltdown (Spectre variant 3), L1T (L1 terminal fault, Spectre variant 5). Trois vecteurs nécessitent toujours un système dexploitation à jour : Spectre, Spectre variant 2, Spectre NG (Spectre variant 4) limpact en performance pourrait être marqué.
Cascade Lake ne marquera donc probablement pas la fin des efforts dIntel sur la sécurité, surtout que des failles de cette famille (toutes exploitent le mécanisme dexécution spéculative, à luvre dans tous les processeurs performants actuels) sont découvertes régulièrement.

Côté réseaux neuronaux
Avec le rachat dentreprises actives spécifiquement dans le domaine des processeurs daccélération pour lapprentissage profond et la vague marketing à ce sujet, il eût été étonnant que ces processeurs naient rien de spécifique à ce sujet. Intel précise donc que Cascade Lake ajoutera un jeu dinstructions dédié : VNNI (vector neural network instructions). Techniquement, VNNI est une extension dAVX-512, des instructions prévues pour fonctionner de manière vectorielle, cest-à-dire quelles effectuent la même opération sur plusieurs valeurs à la fois.
Sur une génération, Intel annonce une augmentation de débit dun facteur 5,4 (entre Skylake et Cascade Lake, donc) pour linférence avec Caffe sur une architecture de réseau neuronal résiduel profond (ResNet 50, très utilisée en reconnaissance dimages). Cela ne signifie pas quune inférence prend cinq fois moins de temps, mais quun processeur peut effectuer cinq fois plus dopérations dinférence sur le même temps (notamment parce que le processeur effectue plusieurs inférences à la fois).
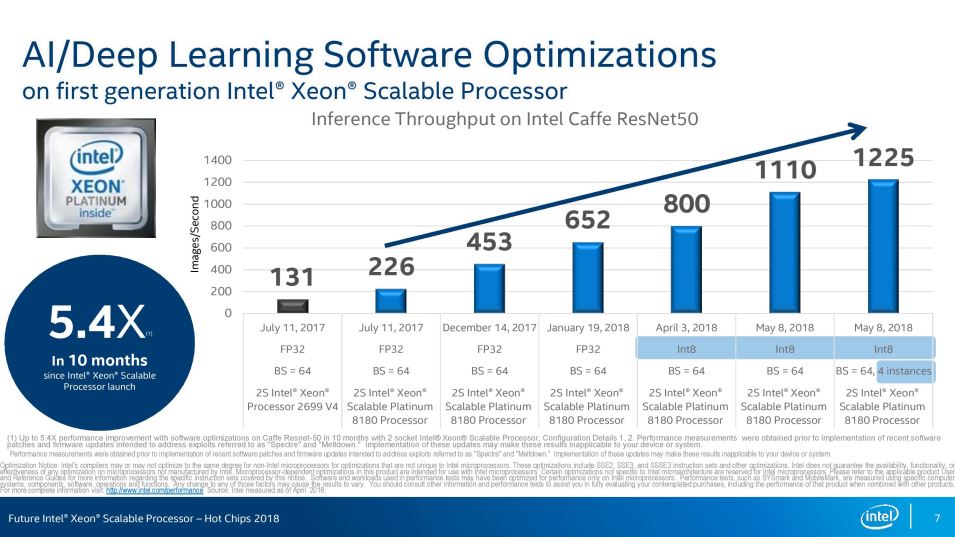
Ce facteur sexplique aussi par des améliorations au niveau logiciel et une réduction de la précision lors des calculs, même si Intel préfère mettre en avant deux instructions en particulier : VPDPBUSD et VPDPWSSD. Elles servent à fusionner plusieurs instructions utilisées lors dune convolution (lopération de base pour le traitement dimages dans les réseaux neuronaux), avec des opérations de type addition-accumulation.

Source et images : Intel at Hot Chips 2018: Showing the Ankle of Cascade Lake.
Vous avez lu gratuitement 171 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.