

 L'apprentissage profond génère de gros besoins en puissance de calcul pour entraîner des réseaux neuronaux profonds sur d'énormes quantités de données. Pour y répondre, de nombreuses sociétés ont développé des solutions adaptées. Par exemple, NVIDIA a commencé par réutiliser ses processeurs graphiques et finit par ajouter des curs tensoriels, Intel et ARM ajoutent des instructions dans leurs processeurs, Intel propose des processeurs entièrement prévus pour cette tâche, Cerebras fabrique les processeurs les plus gros au monde ; de manière plus expérimentale, Intel examine la piste des architectures neuromorphiques.
L'apprentissage profond génère de gros besoins en puissance de calcul pour entraîner des réseaux neuronaux profonds sur d'énormes quantités de données. Pour y répondre, de nombreuses sociétés ont développé des solutions adaptées. Par exemple, NVIDIA a commencé par réutiliser ses processeurs graphiques et finit par ajouter des curs tensoriels, Intel et ARM ajoutent des instructions dans leurs processeurs, Intel propose des processeurs entièrement prévus pour cette tâche, Cerebras fabrique les processeurs les plus gros au monde ; de manière plus expérimentale, Intel examine la piste des architectures neuromorphiques. GraphCore est une jeune pousse active dans le secteur depuis 2016. Elle développe des IPU (intelligence processing unit), des processeurs extrêmement parallèles (comme les processeurs graphiques), mais avec une architecture en carreaux : un processeur contient 1216 carreaux, chacun comportant de la mémoire et six curs de calcul. La puce en elle-même contient 300 Mo de mémoire cache, avec une bande passante de 45 To/s, sans oublier 80 canaux de communication avec d'autres IPU.
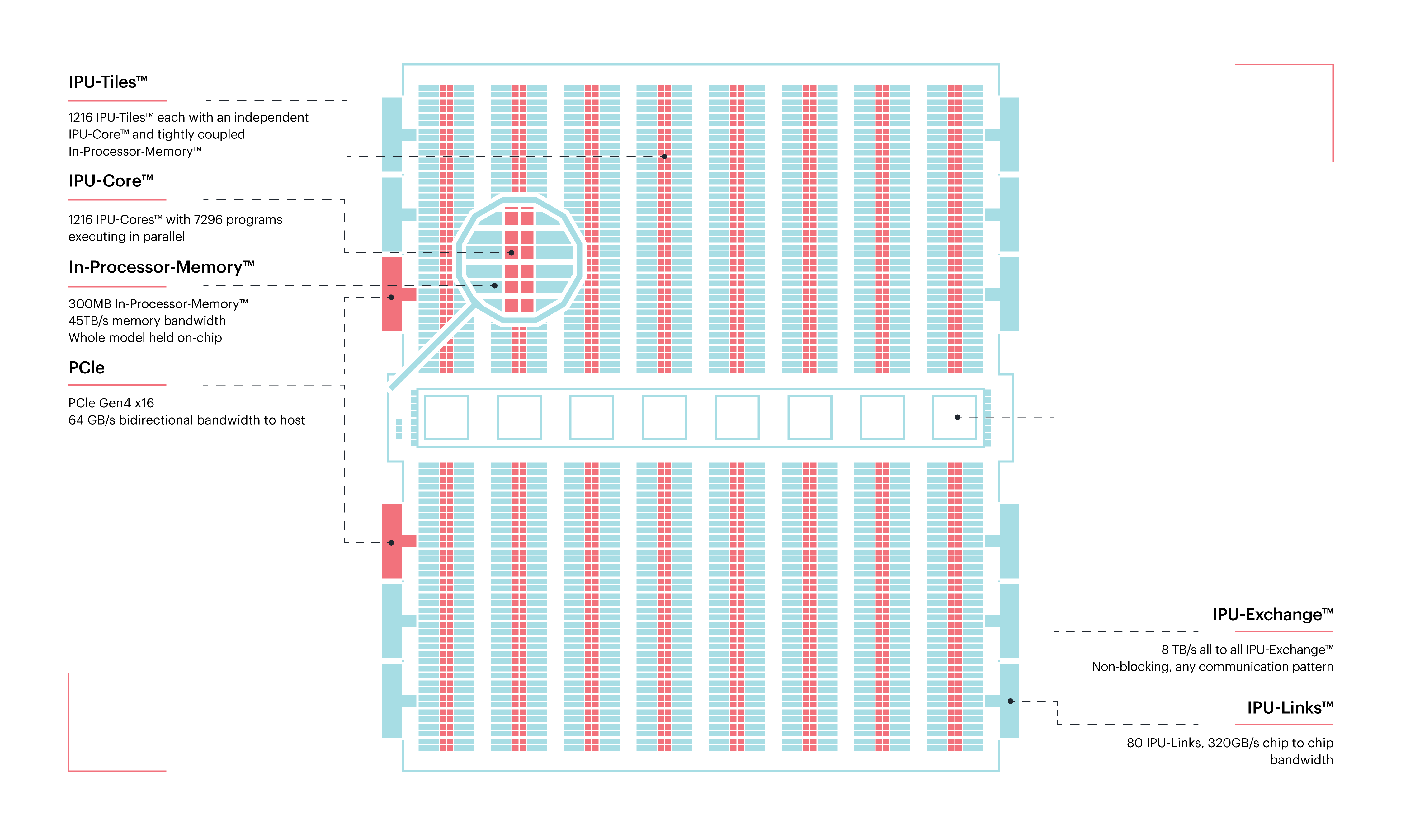
Le premier serveur muni de cette technologie, sous la forme de cartes d'extension PCIe, a été produit par Dell, fin 2018.
Le DSS8440 contient jusqu'à huit cartes produites par GraphCore, chacune contenant deux de ces processeurs. Configuré avec des cartes graphiques, le même serveur peut monter jusqu'à dix cartes. La programmation des IPU se fait à l'aide de Poplar, une bibliothèque orientée graphe, mais des intégrations sont fournies pour TensorFlow et PyTorch. Il est aussi possible de lancer de l'inférence directement sur des réseaux stockés au format ONNX.
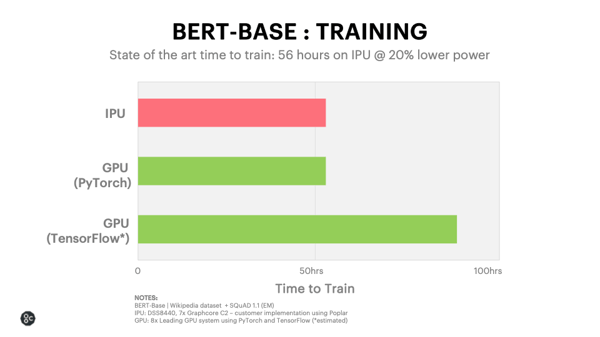
Désormais, les produits GraphCore sont disponibles sans devoir acheter de matériel hors de prix : dans la solution infonuagique Microsoft Azure. Ce fournisseur de service s'était déjà distingué en étant le premier à offrir des FPGA, toujours pour les réseaux neuronaux. Cette solution permet d'entraîner le modèle linguistique BERT sur un corpus de texte en cinquante-six heures, comme PyTorch sur un GPU. Ce faisant, cette nouvelle solution permet de battre TensorFlow d'un facteur deux mais le coupable est probablement TensorFlow, puisque PyTorch effectue les mêmes calculs plus vite.
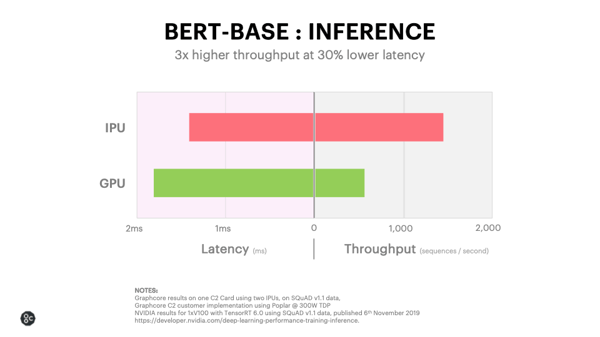
Là où les processeurs GraphCore montrent un intérêt plus grand, c'est au moment de l'inférence : ils peuvent effectuer trois fois plus d'opérations d'inférence par seconde, avec une latence moindre de trente pour cent. Les processeurs graphiques ont tendance à moins bien fonctionner dans ce scénario, puisqu'il faut un paquet de données à traiter pour les utiliser au mieux : si on ne passe qu'un peu de données à la fois, énormément de puissance de calcul ne peut pas être utilisée.
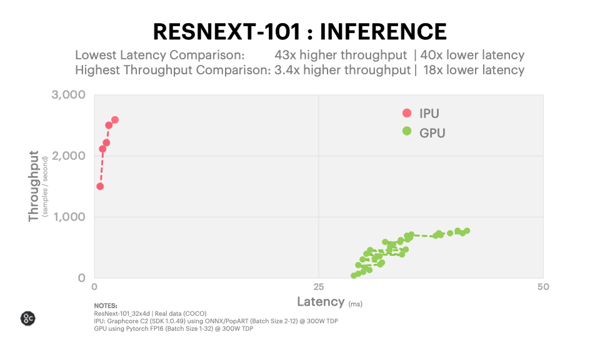
Qwant, le moteur de recherche européen, est l'un des premiers clients de cette technologie (hébergée dans Microsoft Azure). Leur modèle ResNext, utilisé pour la reconnaissance d'images, peut fonctionner bien plus rapidement sur des IPU que des GPU : ils aiment résumer l'impact en termes de performance par un facteur de 3,5. Plus en détail, l'inférence peut fonctionner avec un débit au moins 3,4 fois plus élevé et une latence jusque 40 fois moindre qu'avec un GPU.
Source : communiqué de presse.
Voir aussi : des tests de performance plus poussés (effectués par GraphCore, pas par un laboratoire indépendant).
Vous avez lu gratuitement 13 439 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.